Table of Contents
When building a variation, metric, or audience - be sure to specify "Regex" from the select list.
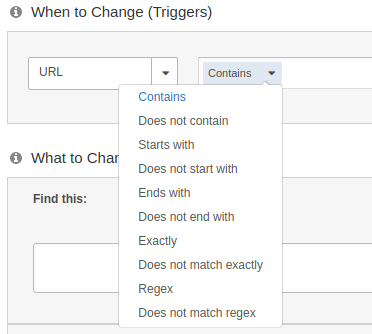
- Most standard regular expressions work in SiteSpect
- Matches as case sensitive by default. (?i) needs to be used to specify a case insensitive match
- At the time of this writing, global variations do not use the select list interface and support regex by default
- Dot star (.*) will match all including newlines \r\n
- \s will match spaces, tabs, and newlines
- SiteSpect adheres to Perl compatible regex
- See more information on regex setup & compatibility
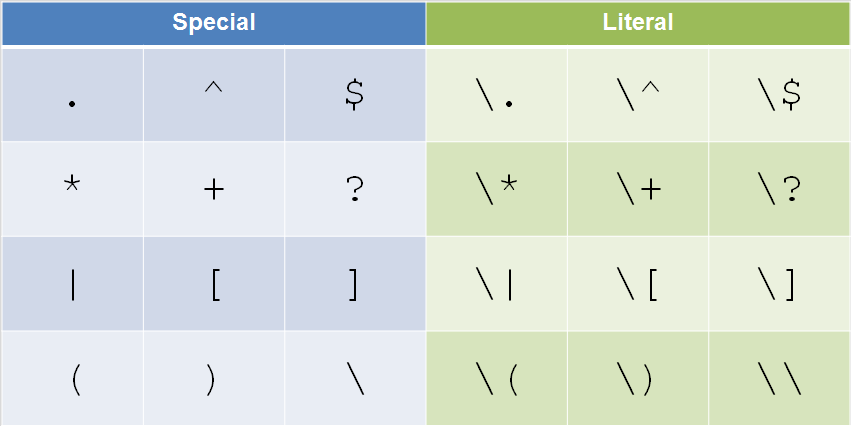
Special Characters in regex
- There are twelve special characters that need to be escaped if intended as literal text. There is a built in function to escape text above each field labeled as ESC (do not double escape).
. ^ $ * + ? | [] () \
- It’s often easier to run ESC and then add regex
- The Variation replacement text does not require escaping with the exception of the backslash and dollar sign followed by a number ($100 \) - although it does not hurt to escape the replacement text
|
Dot |
. |
A dot matches any single character. For example, ab. matches abc and abz and ab_ |
|
Asterisk |
* |
Quantifier: An asterisk matches zero or more of the preceding character, class, or subpattern. For example, a* matches ab and aaab. It also matches at the very beginning of any string that contains no "a" at all. Wildcard: The dot-star pattern .* is one of the most permissive because it matches zero or more occurrences of any character. For example, abc.*123 matches abcAnything123 as well as abc123. |
|
Question Mark |
? |
Quantifier: A question mark matches zero or one of the preceding character, class, or subpattern. Think of this as "the preceding item is optional". For example, colou?r matches both color and colour because the "u" is optional. |
|
Plus |
+ |
Quantifier: A plus sign matches one or more of the preceding character, class, or subpattern. For example a+ matches ab and aaab. But unlike a* and a?, the pattern a+ does not match at the beginning of strings that lack an "a" character. |
|
Caret, Dollar Sign, \A, \z |
^ $ \A \z |
Caret and dollar sign are called anchors because they don't consume any characters; instead, they tie the pattern to the beginning or end of the string being searched. ^ may appear at the beginning of a pattern to require the match to occur at the very beginning of a line. For example, ^abc matches abc123 but not 123abc. $ may appear at the end of a pattern to require the match to occur at the very end of a line. For example, abc$ matches 123abc but not abc123. \A and \z are anchors that match at the beginning and end of a file. Use these if needed in a Trigger Body Match Condition or Variation Search Text. For example, \A(.*?<div class="genericDiv") matches the first occurrence of this because it is anchored. |
|
|
|
Classes of characters: The square brackets enclose a list or range of characters (or both). For example, [abc] means "any single character that is either a, b or c". Using a dash in between creates a range; for example, [a-z] means "any single character that is between lowercase a and z (inclusive)". Lists and ranges may be combined; for example [a-zA-Z0-9_] means "any single character that is alphanumeric or underscore". A character class may be followed by *, ?, +, or {min,max}. For example, [0-9]+ matches one or more occurrence of any digit; thus it matches xyz123 but not abcxyz. Within a character class, characters do not need to be escaped except when they have special meaning inside a class; e.g. [\^a], [a\-b], [a\]], and [\\a]. |
|
[^...] |
Negated character class: Matches any single character that is not in the class. For example, [^/]* matches zero or more occurrences of any character that is not a forward-slash, such as http://. Similarly, [^0-9xyz] matches any single character that isn't a digit and isn't the letter x, y, or z. |
|
|
Vertical Bar |
| |
Alternation: The vertical bar separates two or more alternatives. A match occurs if any of the alternatives is satisfied. For example, gray|grey matches both gray and grey. Similarly, the pattern gr(a|e)y does the same thing with the help of the parentheses described below. |
|
Parentheses |
(…) |
Items enclosed in parentheses are most commonly used to: •Determine the order of evaluation. For example, (Sun|Mon|Tues|Wednes|Thurs|Fri|Satur)day matches the name of any day. •Apply *, ?, +, or {min,max} to a series of characters rather than just one. For example, (abc)+ matches one or more occurrences of the string "abc"; thus it matches abcabc123 but not ab123 or bc123. •Capture a subpattern such as the dot-star in abc(.*)xyz. To use the parentheses without the side-effect of capturing a subpattern, specify ?: as the first two characters inside the parentheses; for example: (?:.*) |
table contents source: https://www.autohotkey.com/docs/misc/RegEx-QuickRef.htm
Regex basic example
The following is probably the simplest and most common regular expression used.
<div id="mktmsg">(.*?)</div>
- This expression will find and capture all content from
<div id="mktmsg"> until it reaches the first </div> - Explanation: . (dot=any character) * (0 or more times) ? (non-greedy, find the first occurrence of what comes after)
The parenthesis ( ) specify that the text matched is put into a system variable called a numbered capture group. Since it is the first match, the variable is $1. Subsequent captured matches are $2, $3, etc.
Regex negated character class
Match unknown content within an HTML tag.
<div id="mktmsg" data-attr="123456" … >
(<div id="mktmsg"[^>]*>)
- This expression will keep matching each character until it sees a >. It’s like saying keep matching while not >.
Explanation: [ ] character class, ^ not, > literal character, * 0 or more times. - Replacement example
$1<span>Added text to top of div</span>
- Character classes tend to be efficient compared to a wild with lazy
Greedy vs non-greedy
- By default, * and + are greedy and will consume all characters until they find the last one.
- To instead have them stop at the first possible match, follow them with a question mark *? +?
<div class=“section1”>some content</div>
<div class=“section2”>some other content</div>
- Lets say you want to capture the content from section1: <div class=“section1”>(.+)</div> will keep going until it finds the last </div> tag from section2
- What you want in this case is:
<div class=“section1”>(.+?)</div>
- Any character (dot), one or more times (plus), stop at first </div> (followed by a question mark)
Example Trigger - Match for a URL Path
- You have a page where the URL is
http://www.example.com/clothing-shoes-jewelry-clothing-men-s-clothing/b-1325284125 - There could be something after the 5 (like ?utm=1234) but you don’t want it to match in that case
- The URL Trigger would look like:
^/clothing-shoes-jewelry-clothing-men-s-clothing/b-1325284125$
- Note: SiteSpect URL triggers are a pathname and do not include the protocol and hostname
Example Trigger - Match for a URL Path that uses a lookahead and lookbehind
Is a pattern followed by another patter, is a pattern not proceeded by another pattern
- You have a page where the URL is
http://www.example.com/clothing-shoes-jewelry-clothing-men-s-clothing/b-1325284125 - You want to match any URL starting with “clothing” followed by “men” anywhere
- The URL Trigger would look like
^/clothing.*?men
- What if you wanted to restrict the search to clothing for men. The URL Trigger would look like
^/clothing.*?-men
OR^/clothing.*?(?<!wo)men
Example Trigger - Match page content
- Find the content you want to operate on
<span class="shcHpSubHeadlineBold">Men's Clothing by Fit:</span>
- Look for something that identifies the page such as a title, comment, or analytics tag declaration:
omsubcategory= "Clothing, Shoes & Jewelry > Clothing > Mens Clothing“
- The full match looks like:
<span class="shcHpSubHeadlineBold">Men's Clothing by Fit:</span>.*?omsubcategory= "Clothing, Shoes & Jewelry > Clothing > Mens Clothing
Example Variation - Replace content
<div class=“section1”>some content</div>
<div class=“section2”>some other content</div>
- Add a class to any div with a class name “opt” starting with section followed by a number
- Search
(<div class=“section[0-9]+)”>
- Replace
$1 opt”>
- This will apply twice (as many times as it can match that pattern)
- Need to “put back” the “> as it is not part of the capture group
Example2 Variation - Replace content
<div class=“section1” data-smeta=“more”>some content</div>
<div class=“section2”>some other content</div>
- Add a class to any div with a class name “opt” starting with section followed by a number
- Search
(<div class=“section[^”]+)(”[^>]*>)
- Replace
$1 opt$2
- This will apply twice (as many times as it can match that pattern)
- Everything that is “put back” is in the capture group variables
Expanded Definitions
A Regular Expression (frequently referred to as regex) is a tool used by many applications to search content for a pattern of text. Regex is not unique to SiteSpect; it is a pattern matching method used by many applications. SiteSpect makes use of regex to perform its search operations.
Regular Expression Characters
In regex, there are basically two types of characters:
-
Regular characters, or literal characters, which means that the character is what it looks like. The letter "a" is simply the letter "a". A comma "," is simply a comma and has no special meaning.
-
Special characters, or metacharacters, which means that the character has a special meaning. The character "?" is not a question mark; it has a special meaning. Likewise, the character "\" is not a backslash; it, too, has a special meaning. Regex makes use of the following special characters to interpret patterns of text:
. ? * + ^ | $ \ ( ) [ ]
If you want use one of these characters as a literal character, you must escape it by placing a backslash before it as follows:
\. \? \* \+ \^ \| \$ \\ \( \) \[ \]
SiteSpect's Escaper Tool
In general, you can perform all of the basic Find or Find and Replace functions of a standard editor's search tool in SiteSpect without learning regular expressions. Enter the literal text (the precise text you want to find, such as "Sign in" or "mysite.com") and then use the Escaper tool (ESC) within that field to automatically replace any characters that have special meanings in regex with their escaped counterparts. This means that it inserts any necessary backslashes to indicate that the character that follows the blackslash should be interpreted literally and not with its special meaning in regex.
How Do Regular Expressions Operate?
The basic regular expressions operate the same way as the Find function in standard editors like Microsoft Word or Notepad. Just like with the Find function, you ask the application to locate a string (or pattern) of text that you want to find. Sometimes, you may want to replace that text with a different string of text, but sometimes, you may want to carry out some other text manipulation task such as changing the order of your content.
For example, you can use regex to search for the text "Sign in" using the following search text: Sign in. It looks very similar to using the Find function in a text editor. You simply search for the literal text you want to find.
The advanced regex features allow you to search with more flexibility. With regex you can:
- Search for a string from a list of possible text strings.
- Find multiple text strings in a single search.
- Use wildcards or ignore the text between terms you are searching for.
- Copy or rearrange the text found by the search.
For example, to find either "Sign in" or "Sign out" you can use the regex: Sign (in|out). In regex, the pipe (|) character is a special character that means find either the part of the pattern on the left or the right side of the pipe.
Wildcards
You may already be familiar with wildcards when looking for files on your computer. The expression *.doc uses a wildcard character, the asterisk, which represents zero or more characters. The entire expression searches for filenames with zero or more characters followed by the extension ".doc".
Regex allows you to use many different types of wildcard searches, but the most useful one in SiteSpect is the collection of special characters .*?. Taken together, they constitute a wildcard search that finds the next pattern to the right only after finding the pattern to the left. In order to work, it must have text before and after it.
For example, the pattern Subtotal.*?\$ searches for the text "Subtotal" and then uses the wildcard to match any number of characters until it finds the next "$", a literal dollar symbol.
Alternation
Alternation uses the pipe character (|) as an OR operator within the Search field. You can replace each instance of the pipe character with the word "or" such that, for example, the pattern this|that|those means "this or that or those". In another example, to match the checkout page or the cart page, use a pattern similar to the following: /(cart|checkout), which means match the "/cart" URL or the "/checkout" URL.
Grouping
In regular expressions, parentheses create groupings. When you enter search text, you can create a group within parentheses to constrain the alternation character; the result is that the "or" applies only to what is within the parenthesis.
In the example, th(is|at|ose), the parenthesis surround "is|at|ose". This regex is the same as saying "this or that or those," but in a more efficient manner. When testing the search text for matches against the content, SiteSpect first looks for the "th" and then it looks for one of "is" or "at" or "ose" following the "th" that it already found. If you were trying to match this|that|those without using grouping, SiteSpect would have to start its comparison process from the beginning of the content for each member of the group. Using grouping, SiteSpect searches the content only once.
As a second example, to match the books category, movies category, or electronics category pages you might use a pattern similar to /category/(books|movies|electronics), which looks for a "/category/" directory in the URL followed by either "books", "movies", or "electronics".
Constraining alternations with groupings also works in Search & Replace. However, in a Search & Replace operation, groupings in the search text are primarily used to capture, or remember, the text matched by the pattern within the parenthesis for later use in the replacement text. Groupings and wildcards are frequently used together because they allow you to match and remember all of the text matched by the wildcard.
In the replacement pattern, you can reference the text in the capture groups using capture group variables, which is like a variable in computer programing. In SiteSpect, capture group variables are sequential and have the form "$#"; a dollar sign followed by a number. The number of a capture group is determined by the count of open parenthesis in capture groupings. The first capture group is stored in $1 and the second $2 and so on.
Capture groups are read left to right. This means that in the following expression...
(I am) (reading the (SiteSpect) user guide.)
the capture groups are numbered as follows:
$1 = I am
$2 = reading the SiteSpect user guide.
$3 = SiteSpect
For example, if you want to add the message "(not including tax)" to the subtotal of the cart page, you would search for the subtotal on a page by using the search pattern (Subtotal.*?)\$. When this pattern matches the text matched by Search.*?, it is stored in the capture group variable $1 because it is the first capture group in the search pattern. Every character matched by .*? within the capture group is stored in $1 in addition to the literal text "Subtotal". To insert the message directly before the dollar sign, use a replacement pattern like $1 (not including tax) \$. Note that the parentheses in replacement patterns are not special characters so they do not create additional capture groups. There are only two characters that are special in the replacement text; the dollar sign “$”, and the backslash “\”. Both of these need to be escaped if they are intended to be literal. The dollar sign is a special character in regular expressions because it is used to indicate a capture group variable. Any dollar sign followed by a number is replaced by a capture group variable (if present). To avoid this, escape all dollar values in the replacement text.