In this article:
- Understanding Group Sequential Testing in A/B Testing
- How to Run a Campaign with Sequential Testing in SiteSpect
- How to Enable
Understanding Group Sequential Testing in A/B Testing
Group sequential testing is an advanced statistical framework used in A/B testing that allows for interim analysis of data at predefined points throughout the experiment. Unlike traditional fixed horizon testing, where decisions are made only at the end of the testing period, group sequential testing enables earlier decision-making by periodically evaluating the results. This method can be particularly beneficial in A/B testing scenarios, such as marketing campaigns or user experience studies, where timely insights can lead to quicker optimization and resource savings.
Problems with Fixed Horizon Testing
Fixed horizon testing, while straightforward, has several limitations. One major issue is the potential waste of time and resources, as the experiment must run its full course before conclusions can be drawn, regardless of early emerging patterns. This can result in prolonged testing of ineffective variants, consuming resources that could be better utilized elsewhere.
A common problem associated with fixed horizon testing is the temptation to "peek" at the data before the test concludes. Peeking can lead to biased results and an increased risk of Type I errors, as early looks can distort the statistical significance due to random fluctuations in the data.
Moreover, fixed horizon testing is vulnerable to temporal effects, such as seasonality or market trends, which can influence user behavior and confound the results if the testing period is too long. These external influences can obscure the true effects of the variants, leading to less reliable conclusions.
By addressing these issues, group sequential testing offers a more efficient and accurate approach to A/B testing.
How Sequential Testing Addresses These Problems
Group sequential testing addresses the limitations of fixed horizon testing by incorporating interim analyses, allowing for earlier decisions when sufficient evidence is available. This method divides the testing period into several stages, with pre-specified points for data analysis. If results at any interim analysis are conclusive, the test can be stopped early, saving time and resources.
Sequential testing also mitigates the risk of peeking by providing a structured framework for interim analyses, reducing the temptation to check data prematurely. This helps maintain the integrity of the test and prevents the increased risk of Type I errors associated with unscheduled peeking.
Additionally, sequential testing helps counteract temporal effects by offering multiple checkpoints throughout the testing period. This enables earlier identification of trends and anomalies, leading to more accurate and timely insights and enhancing the reliability of A/B test results.
How to Run a Campaign with Sequential Testing in SiteSpect
Running a campaign using the sequential testing method involves two main steps. You start with a pre-test planner to define clear objectives, hypotheses, and metrics, and determine the timing and criteria for interim analyses and stopping rules. This step ensures the test is designed to produce valid and reliable results.
Once your campaign is running, the interim checkpoints will evaluate the data at pre-specified times. At these points, the data is analyzed to see if early conclusions can be drawn—either to stop the test early due to significant results or to continue if more data is needed. This helps in saving resources and implementing successful changes promptly.
Once the campaign has reached the full estimated number of visits, the final checkpoint will let you know whether your KPI was statistically better, worse, or unchanged, for all of your variations. At which point, you can stop your campaign, promote the winner if you have one, or iterate on your idea with a new campaign.
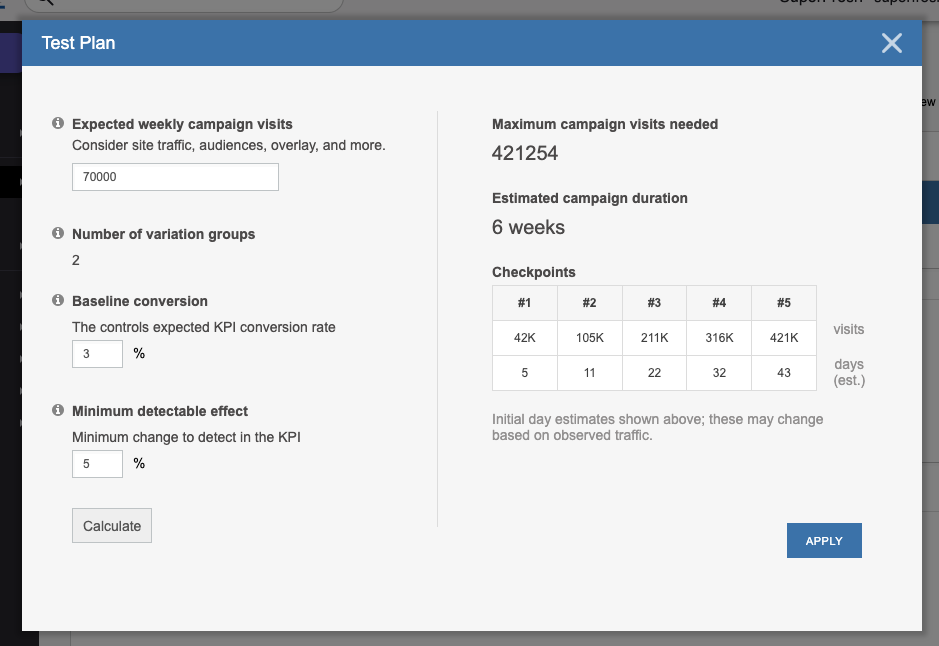
Create Your Test Plan
- Before you set your campaign live, you will need to complete the test plan. This can be found in the main three-dot menu at the top of your campaign:
- In the test plan, you will need to estimate the traffic that will go to this campaign, the baseline conversion rate for your KPI, and the amount of change that you want to test for (MDE).
- Expected weekly campaign visits:
This is the number of visits you estimate will be counted in your campaign in a week. Unless your campaign is testing all pages and all traffic, this number will be lower than your overall site traffic. Consider audiences, counting, and overlay campaigns when calculating.
This number affects the estimated duration, but not the total number of visits needed. - Baseline conversion:
The typical conversion rate for your KPI. Smaller conversion rates need more visits to reach a conclusion. If your estimated duration is very long, you may want to consider using a KPI that is closer to the change that you are testing. For example, you may want to measure add-to-cart instead of checkout conversion.
Not all metrics are equally suited to a sequential test plan. Read more about guidelines and best practices for selecting your KPI. - Minimum detectable effect:
The minimum detectable effect (MDE) is the smallest change that an experiment can reliably detect. Typical MDEs range from 2–10%. Smaller MDEs require more visits.
You can read more about minimum detectable effects here.
- Expected weekly campaign visits:
- The test plan will provide you with a maximum number of visits needed to prove your hypothesis, and the schedule for each checkpoint, which occur after 10%, 25%, 50%, 75%, and 100% of the max campaign visits. Durations are based on the estimated traffic entered and can change depending on actual traffic to the campaign.
- You can try different configurations by adjusting the numbers and clicking “Calculate”. Once you’ve decided on a test plan, clicking “Apply” will save it to your campaign and will overwrite any previous plans that were saved.
As with all testing, the best practice is to let your campaign run for a minimum of two weeks to ensure a representative sample of users have been exposed to your test. If you have high traffic or are using a KPI with a high conversion rate, you may want to consider lowering the frequency of your campaign.

Checkpoints, Alerts, and Conclusions
Once you’ve designed your test plan and set your campaign live, SiteSpect will monitor the KPI and determine if it has reached a conclusion. You’ll get emails and see alerts on the campaign at the predetermined checkpoints advising whether the campaign has reached a conclusion and is ready to end, or if you should let it continue running.
Checkpoints are assessed nightly, so keep in mind that the actual visits at a checkpoint will not be exactly the same as the test plan. Checkpoints are scheduled to run at 10%, 25%, 50%, 75%, and 100% of the maximum number of campaign visits calculated in your test plan.
These are the alerts and conclusions that you will see:
- Needs more time
You will see this alert at one of the first four checkpoints if the KPI has not yet reached a conclusion. No action is required at this time, you can let your campaign continue on to collect more data. - Won!
You’ll see this alert when the KPI on one of your variations has crossed the winning boundary. At this point you should review your secondary metrics, end the campaign, and promote the winning variation if appropriate. - Lost
You’ll see this alert when the KPI on one of your variations has crossed the losing boundary. At this point you should review your secondary metrics, end the campaign, and plan for any follow up iterations if appropriate. - Inconclusive
You’ll see this message at the final checkpoint if your KPI has not reached a statistical conclusion. If you’re testing a new feature, an inconclusive test might tell you that while it did not result in an increase in conversions, it should be safe to push live without much harm. As always, it’s best to review your secondary metrics, end the campaign, and plan for any follow up iterations if appropriate.
In addition to alerts, you will have access to a new report with the analytics section of your campaign. This chart will show you a visual representation of the sequential results for the KPI at every checkpoint. This can help you see trends over time in addition to alerting you to winning and losing variations.

SiteSpect stops checking after the final checkpoint, so letting the campaign run longer will not result in any new conclusions.
Supporting Metrics
In conjunction with the test plan and checkpoints, which provide guidance and results on your KPI, enabling a sequential test plan on your campaign will help minimize type I errors for your supporting metrics.
Every metric in a campaign requires a uniquely calculated traffic volume to assess statistical significance properly. Since not all metrics will be ready simultaneously, reviewing a matrix of metrics, particularly when the campaign is running, results in dozens of peeking scenarios and opportunities for drawing incorrect conclusions due to the accumulation of type I error probability.
To control these factors and minimize false positives, we apply a Bonferroni correction to the non-KPI metrics and provide a conclusion indicator to alert you to metrics that have reached significance. The conclusion indicator is a single indicator that identifies when one of your supporting metrics has reached 95% on the Bonferroni-corrected significance level.
We have also removed the potentially misleading predictive statistics in the performance matrix and trend report, including percent significance and the confidence plot. Only campaigns with a sequential test plan have this additional statistical framework applied to supporting metrics.
Some Sequential Testing Best Practices
Plan ahead
- The Test Plan of the sequential test requires baseline data that should be collected prior to the experiment run, including the amount of traffic expected to satisfy the requirements for inclusion, and the baseline conversion rate of the KPI.
- Consider using a baseline campaign that is identical to the planned experiment, with the exception of the change(s) themselves. This would include the same audience(s), trigger(s), and KPI as the experiment, and should ideally run for at least a week prior to running the actual experiment.
Be mindful of multiple comparisons
- If your experiment includes multiple hypotheses, consider running the sequential test for the hypothesis with the largest fixed horizon sample size.
- For the other hypotheses, use the fixed horizon approach and interpret those results as sample sizes are reached.
- Be sure to determine the appropriate alpha levels to minimize the accumulation of type I error probability. For example, consider the case of testing three hypotheses concurrently at α = 0.1. Together, these three hypotheses add up to a 30% probability of at least one false positive. The built-in Bonferroni correction for supporting metrics will reduce this risk, but depending on the goals, you may also consider moving some hypotheses to follow-on experiments.
Sample Size Calculators
When planning for a Group sequential test we recommend you run some simulations on the data inputs using our online calculator here.
How to Enable
Group sequential testing is an industry-standard method to help take the guess-work out of knowing how long to run your campaigns. Sequential testing is available in beta today. If you’re interested in trying this out for yourself, contact helpdesk or your account team to have them enable it for you.